在python爬虫中:使用requests + selenium就可以解决将近90%的爬虫需求,那么scrapy就是解决剩下10%的吗?
这个显然不是这样的,scrapy框架是为了让我们的爬虫更强大、更高效的存在,所以我们有必要好好了解一下scrapy框架。
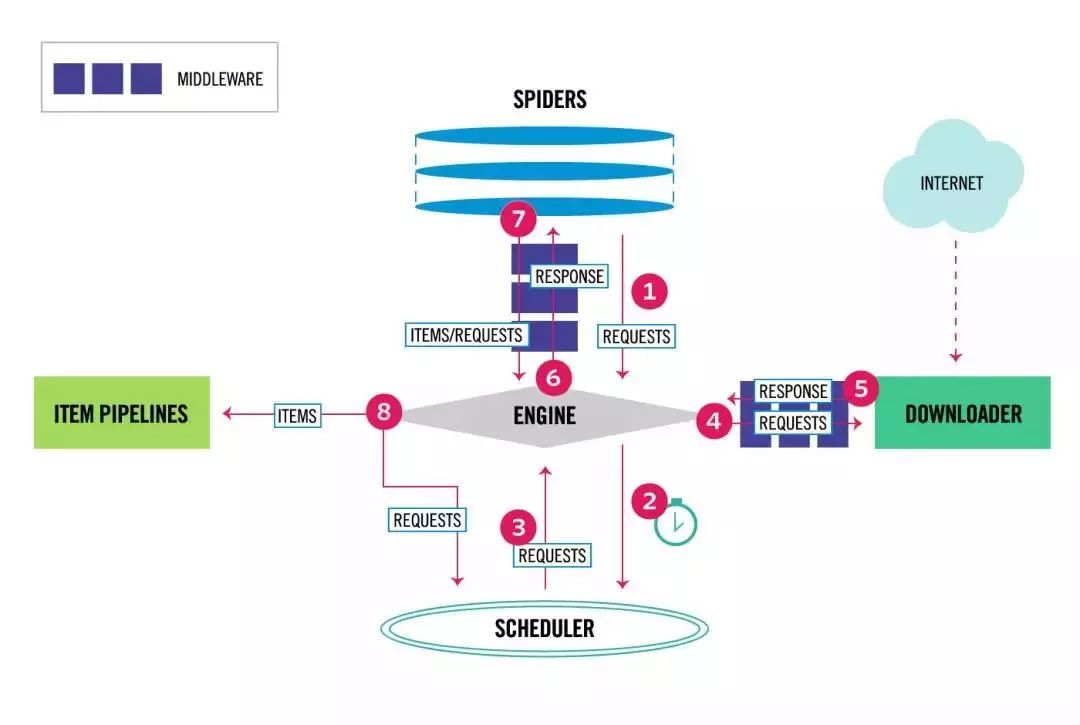
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
框架:用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容以及各种图片
可以应用在很多场景下:
数据挖掘、信息处理、存储历史数据等一系列的程序中,scrapy使用twisted这个异步网络库来处理网络通讯,结构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求